
본 글은 책으로 출판하기 전에 독자 입장에서 소재의 적합성이나 난이도 등을 조사하기 위해 공개한 샘플 원고입니다. 때문에 본 블로그의 다른 글과는 문체나 진행 방식이 상이합니다. 원고에서 사용된 각주는 본 글에서는 인용 형태로 추가하였습니다.
측정할 수 없으면 개선할 수 없다(If you can’t measure it, you can’t improve it).
흔히 유명한 경영학자인 피터 드러커(Peter Drucker)가 한 이야기로 알려져 있으나, 실제로는 그렇지 않다. 피터 드러커는 측정의 중요성뿐만 아니라 측정 불가한 요소들의 중요성도 강조했다.
의도와는 다르게 “측정” 자체에 무게가 실려 많은 IT 개발자의 미움을 산 금언이다. 하지만, 조금 다른 관점에서 본다면 성급한 최적화를 피하고 측정 결과를 바탕으로 최적화해야 함을 강조하는 의미로 이해해 볼 수도 있다. 이미 소개했듯이 프로그램을 작성하는 단계에서 성능에 대한 집착은 되려 부정적인 결과를 가져온다. 가장 이상적인 그림은 프로그램 작성과 최적화 단계를 분리하여 최종적으로 프로그램의 구조적 아름다움과 좋은 성능이라는 두 마리 토끼를 모두 잡는 것이겠지만, 아직 경험이 부족하다면 이는 말 그대로 이상에 불과하다. 설계 단계에서 성능에 대한 고민을 완전히 배제하면 최적화를 진행할 때 처음부터 공들였던 설계가 근간부터 흐트러지는 경우도 적지 않기 때문이다. 어느 정도 경험이 쌓이면 이런 불상사를 피해 가는 요령이라도 터득하겠지만, 그때까지는 설계 단계에서 성능을 고민하지 말라고만 강요하는 것이 항상 정답은 아닐 수 있다. 이제부터 설계 단계부터 고민해 볼 수 있는, 혹은 그럴 가치가 있는 성능 문제를 나눠볼까 한다.
잠시 화제를 바꿔 사람의 뇌를 이야기해보자. 뇌는 우리 몸에서 에너지를 무척이나 필요로 하는 기관이다.
성인 기준으로 뇌 무게는 보통 체중의 3% 정도이지만 총 산소 소모량의 20%, 기초 대사량의 10%를 차지한다.
우리가 하는 작은 행동 하나에도 대부분 뇌가 관여하고 있고, 일정 상황에서 같은 행동을 반복하면 뇌는 이를 “습관”으로 만들어 에너지를 절약하려 애쓴다. 예를 들어, 이사하고 처음 출근하는 초행길에 뇌는 제법 많은 에너지를 소비하며 길을 잃지 않도록 노력하지만, 이후 같은 길을 반복하여 다니면 뇌는 이를 습관으로 삼아 적은 에너지를 쓰고도 같은 목적을 이룰 수 있도록 해준다. 우리가 출근길을 거쳐 색다른 목적지로 향할 때 내릴 곳을 지나쳐 습관대로 가고 있어 당황하는 이유이기도 하다.
앞서 배운 최적화의 가장 중요한 원칙 중 하나는 수행 시간의 다수를 차지하는 부분부터 개선해야 한다는 것이었다. 비슷한 논리를 프로그램이 실행되는 전체 경우로 확장해보자. 프로그램이 실행되는 모든 가능한 경우의 평균적인 성능을 끌어올리는 것보다, 드물게 실행되는 특수한 경우의 성능을 포기해서라도 흔하게 쓰이는 보통의 경우에 좋은 성능을 내는 편이 유리하다. 마치 우리 뇌가 반복되는 일상을 습관화하여 효율을 높이듯, 우리가 만든 프로그램도 “일상”에서 더 좋은 성능을 내도록 하는 것이다.
모든 프로그램이 그러하듯 시스템 프로그램에도 “일상”이 존재한다. 컴파일러를 생각해보면, 컴파일러에 던져지는 대부분의 입력은 대체로 일정한 범주 안에 든다. 간혹 경고 몇 개를 내주어야 하는 경우도 있으나 대부분은 오류 없는 일정한 크기의 소스 코드이다. 특히나 컴파일러가 구현한 언어의 기능 중에는 이런 보통 프로그램에서는 사용되지 않는 것들도 있다. C 언어의 삼중자(trigraph)가 대표적이다.
삼중자는 C 언어를 직업으로 매일같이 사용하는 이들도 좀처럼 알지 못하는 기능으로, 물음표 2개로 시작하는 문자열(예를 들면, ??!)로 다른 문자(|)를 표현하는 방법이다. 삼중자가 도입된 이유를 떠나
마이크로소프트(Microsoft)사의 컴파일러는 C++ 컴파일러지만 C++도 삼중자를 지원하기 때문에 삼중자에 대해 비교적 성실히 설명하고 있다. https://msdn.microsoft.com/ko-kr/library/bt0y4awe.aspx 를 참고하자.
그 처리 방식 때문에 도입 과정에서 논란이 있었으나 쓸모가 있든 없든 C 언어 컴파일러라면 이를 구현하는 것 말고는 다른 방도가 없다. 그러지 않고는 표준을 지원하는 컴파일러라 불릴 수 없기 때문이다.
언어 설계 과정에서 삼중자에는 삼중자를 사용하지 않는 대다수 프로그램을 처리하는데 부담이 되지 않도록 많은 고민이 담겨 있다. 예를 들어, 삼중자는 프로그램 소스를 처리하는 가장 첫 단계에서 처리되며 그 이후 단계에는 영향을 주지 않는다. 일단 컴파일러가 소스를 읽어 들이는 과정에서 삼중자를 대응하는 문자로 치환하고 나면 이후에는 삼중자를 쓰지 않은 소스와 같은 과정을 거친다. 결국, 소스 코드를 입력받는 첫 단계에 약간의 공만 들이면 이후 단계에서 삼중자 처리에 대한 걱정은 필요 없다. 간단한 코드를 통해 예를 보자. 소스 코드를 문자 단위로 읽어 들여 일종의 단어에 해당하는 토큰(token)으로 인식하는 어휘 분석기(lexical analyzer 혹은 lexer)에서 논리 OR 연산자(||)를 인식하는 코드는 매우 간결하다. 아래 코드에서 포인터 p는 입력 라인에서 현재 처리해야 할 문자를 가리키고, OROR과 OR은 각각 논리 OR 연산자와 비트 OR 연산자를 표시하는 매크로 상수(macro constant)나 열거 상수(enum constant) 정도로 생각하면 된다.
switch(*p) {
// ...
case '|':
if (*++p == '|') {
p++;
return OROR; // || 인식 완료
}
return OR; // | 인식 완료
코드는 주석이 무색할 정도로 단순하다.
실제로는 대입 연산자의 일종인
|=에 대한 처리도 필요하나 나누고자 하는 주제와 크게 관련이 없어 생략하였다.
| 문자 이후에 |가 연이어 나오면 논리 OR 연산자, 그렇지 않으면 비트 OR 연산자로 인식한다. 이 과정에서 |로 치환되는 삼중자 ??!를 고민하지 않아도 되는 이유는 삼중자가 이미 앞 단계에서 치환되어 있기 때문이다.
하지만, 요새 주류 컴파일러들은 친절한 에러 메시지를 통해 디버깅을 돕기 위해 오류 위치를 정확히 알려주려 한다. 이때 원본 코드를 인용하여 위치를 명확히 꼬집어 주거나 고급스러운 *통합개발환경(IDE, integrated development environment)*에서는 소스 코드 편집기에 밑줄을 쳐주는 등의 방법을 사용한다.

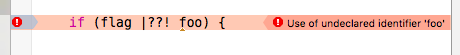
이처럼 고급스러운 기능을 지원하려면 삼중자 처리 방식이 달라져야 한다. 원본 소스 코드를 있는 그대로 기억하지 못하면 오류 위치를 표시할 때 오차가 발생하기 때문이다. 결국, 처음 삼중자를 도입할 때의 의도와 달리 요즘 컴파일러들은 입력 초반에 삼중자를 제거하지 못하고 토큰을 인식하는 단계까지 끌고 간다. 또한, 논리 OR 연산자의 실제 모양이 || 외에는 없었던 시절과 달리 실제 소스 코드에 쓰인 토큰의 모양(스펠링, spelling)을 기억하기 위해 버퍼를 할당하고 문자를 복사해 둘 필요도 생긴다. 이제 코드가 복잡해지기 시작한다.
switch(*p) {
// ...
case '|':
NEWBUF(*p++); // 버퍼 할당 후 | 저장
if (*p == '|') {
putbuf(*p++); // 버퍼에 || 저장
return OROR;
}
if (p[0] == '?' && p[1] == '?' && (c = trigraph(p[2])) == '|') {
putbuf('?'); // 버퍼에 |??! 저장
putbuf('?');
putbuf('!');
p += 3;
return OROR;
}
return OR;
trigraph()는 삼중자를 만나면 치환할 문자를 반환하고, 그렇지 않으면 0을 반환하는 함수이다. | 문자를 인식한 후 이후 문자가 (일반적인 경우에 해당하는) |인 경우와 삼중자 ??!가 나오는 경우를 검사하고 그렇지 않으면 비트 OR 연산자로 인식한다.
문제는 여기서 끝이 아니다. 입력 초반에 미리 처리해야하는 골치 아픈 문제 중에는 삼중자 이외에도 라인 연결을 위해 사용하는 백슬래시(baskslash, \)+개행문자(newline) 조합도 있다.
개행문자 앞에
\n같은 확장열(escape sequence)에 사용하는 백슬래시를 붙였다 하여 escaped newline이라고도 부른다.
긴 매크로를 여러 줄에 걸쳐 정의할 때 자주 사용하는 라인 연결은 보통 사람의 이해를 돕기 위한 목적으로 사용하지만,
#define RETURN(i, s) \
do { \
t->id = (i); \
t->spell = (s); \
return t; \
} while(0)
아래처럼 기괴한 코드도 정상적인 입력이라서 컴파일러 입장에서는 문제가 된다.
if (cond |\
| error) { // cond가 참이거나 err가 참이면
이 역시 소스 코드를 처리하는 입력 초반에 일괄적으로 처리해주고 이후 과정에서는 본디 하나의 라인이었던 것처럼 다루면 간편하다. 하지만, 오류 위치를 표시해 줄 때 원본 소스의 개행문자에 대한 정보가 없으면 전혀 엉뚱한 라인을 가리킬 수 있기에 앞서 삼중자와 같은 고민이 필요하다.
이를 모두 고려하여 코드를 수정하면 이런 모양이 된다. (토큰을 인식할 때 백슬래시와 개행문자 조합을 다루기엔 너무 까다로워 사전에 백슬래시+개행문자를 개행문자 하나로 치환해 두었다고 가정하자.)
switch(*p) {
…
case '|':
NEWBUF(*p++); // 버퍼 할당 후 | 저장
while (*p == '\n') // 라인 연결 인식
putbuf(*p++);
if (*p == '|') {
putbuf(*p++); // 버퍼에 || 저장
return LEX_OROR;
}
if (p[0] == '?' && p[1] == '?' && (c = trigraph(p)) == '|') {
putbuf('?');
putbuf('?');
putbuf('!');
p += 3;
return LEX_OROR;
}
return LEX_OR;
고작 논리 OR 연산자(||) 하나를 인식하는 코드가 이토록 복잡해졌다. 하지만, 이렇게 인식하지 않으면 뒷부분에서 소스 코드 원본에 논리 연산자가 어떻게 입력되어 있는지 확인할 방법이 없다.
이쯤 되면 조금 억울한 면도 있다. 보통의 프로그램 코드 어디에서도 논리 OR 연산자를 |??!로 쓰거나 하필 |와 |사이를 개행으로 나누어 라인을 연결하는 경우는 흔치 않다. 결국, 오로지 표준 준수 여부를 확인하는 테스트 프로그램에서나 쓰이는 경우를 대비한 코드가 정상적으로 비트/논리 OR 연산자를 사용하는 수많은 프로그램의 처리 성능을 떨어뜨리는 결과를 초래한다 - 비트 OR 연산자 하나를 인식할 때 얼마나 많은 검사를 거치는지 보자. 앞서 뇌의 경우로 치면 평생 한 번 만날까 말까 한 경우를 위해 일상적으로 반복되는 상황을 습관으로 만들지 못하고 비효율적으로 동작하는 셈이다.
아주 특수한 상황에서 특수한 목적으로 사용되는 경우를 느리게 할지라도 실행 상황의 대부분을 차지하는 "일상"을 습관화한다면 아래와 같이 코드를 수정해 볼 수 있다.
switch(*p) {
case '|':
if (*++p == '|')
return LEX_OROR;
if (*p != '\n' && *p != '?')
return LEX_OR;
NEWBUF('|'); // 버퍼 할당 후 | 저장
while (*p == '\n') // 라인 연결 인식
putbuf(*p++);
// 이하 동일
대단한 수정 사항도 아니다. 삼중자와 라인 연결을 지원하는 복잡한 코드 앞에 일반적일 때를 처리하기 위한 코드를 추가했을 뿐이다 - 실제 컴파일러 코드에서는 조금은 복잡한 고민이 필요하지만, 근본적인 접근은 다르지 않다.
실제 코드가 궁금하다면 https://github.com/mycoboco/beluga/blob/master/lib/lex.c 에서 확인할 수 있다.
덕분에 약간의 중복 코드가 들어가지만, 다수에 해당하는 보통의 경우에는 처음 구현했던 코드처럼 큰 낭비 없이 처리 가능하다. 대신 삼중자나 라인 연결이 사용된 드물고 특수한 경우는 처음 코드와 비교해 아주 약간의 성능 저하가 있을 뿐이다.
이런 접근을 통해 성능이 개선될 수 있다는 혹은 최소한 큰 손해를 보지는 않을 것이라는 추측은 성능 측정 이전에도 충분히 가능하다. 더구나 애초에 설계 과정에서 프로그램의 “일상”에 대해 고민하고 그 결과가 반영된 탓에 나중에 최적화를 위해 설계를 크게 갈아엎을 일도 없고 제법 아름다운 설계를 유지하는 것도 가능하다.
실제 "일상의 습관화"를 통해 컴파일러는 더욱 친절한 오류 메시지를 제공할 능력을 갖추면서도 성능에는 큰 영향을 받지 않게 된다. 아래는 컴파일러 구현에 사용된 소스 파일 하나를 동일 환경에서 두 가지 버전으로 컴파일하며 수행 시간을 측정한 결과이다.
| 삼중자, 라인 연결을 초반에 제거하는 버전 | 삼중자, 라인 연결을 어휘 분석기에서 인식하는 버전 | |
|---|---|---|
| 수행 시간 (100회 반복, 5회 측정 후 평균) | 5.788초 | 5.709초 |
오히려 “일상의 습관화”와 더불어 적용한 약간의 최적화 때문에 원래 버전보다 복잡한 기능을 지원하면서 더 나은 성능을 보이는 의외의 결과를 확인할 수 있다.
최적화라는 것이 그 이름이 주는 무게감과는 달리 항상 어려운 작업만을 의미하는 것은 아니다. 때로는 시스템이나 언어에 대한 깊은 이해를 바탕으로 깔아야 하는 경우도 있지만, 때로는 자신이 만드는 프로그램을 사용할 사용자의 입장에서 약간만 고민한다면 그리 큰 노력을 들이지 않고 제법 쓸만한 결과를 얻는 경우도 있다.
- 집합과 명제, 그리고 공진
- 일상의 습관화를 통한 최적화